

word2vecを提案したトマス・ミコロフラによって新たに開発された、word2vecの延長線上にあるライブラリ。単語埋め込みを学習する際に単語を構成する部分文字列の情報も含める。そのことで訓練データには存在しない単語(Out of Vocabulary,OOV)であっても単語埋め込みを計算したり、活用する単語のの互換と語尾を分けて考慮したりすることを可能にした。
Facebook AI Researchが開発したfastTextは自然言語処理を高速、高精度化するために有効な機械学習ライブラリである。
fastTextの単語のベクトル化は、文章を構成する単語を複数の特徴に対する関連の度合いを0〜1の間の実数で表現するものである。したがって、基になる文章の量が多く、取り扱う分野が多くとも、このベクトルは高次元でも256次元以上、つまり特徴の項目数が256個以上程度となる。fastTextはディープラーニングを用いてテキストデータからベクトル化されたモデルを獲得する。
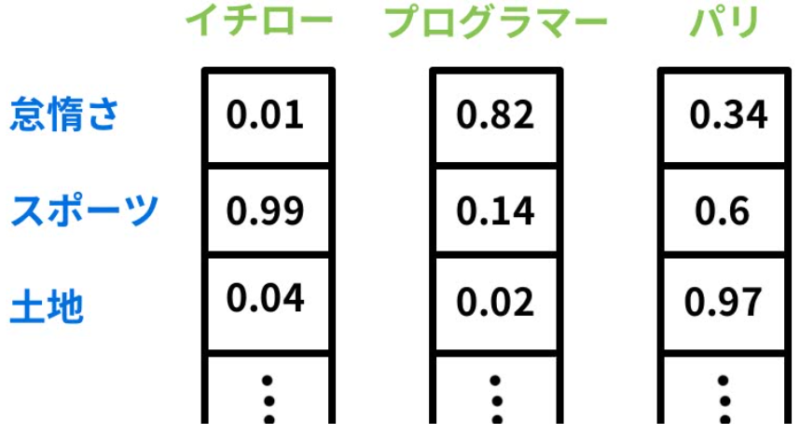
テキスト分類とは、単語のベクトルを用いて同じ特徴の数値が高い単語をそれぞれのグループに分類することである。テキスト分類の基本的なアルゴリズムは、2値分類タイプのSVM(Support Vector Machine)やNaïve Bayesianがこれまで標準的であった。しかし、これらのアルゴリズムをマルチクラスの問題や不均衡データに活用しようとすると非常に処理負荷が高くなるという問題があった。それに対してfastTextは、テキストの分類にCBOW(Continuous Bag-of-Words )、skip-gramの2種類のアルゴリズムをニューラルネットワーク上で実現している。
