

GPTの後継で2019年2月に登場。約15億のパラメータを持ち、GPTでは行えなかった機械学習などの言語生成タスクも行える。
一言で簡単にGPT-2といえば、「transformer + zero-shot learning + big data」だと思います。
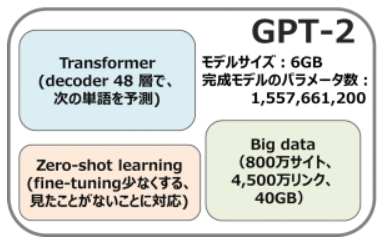
GPT-2のアーキテクチャーは特に新しいものではなく、48層decoderのみのtransformerの拡大版です。それにもかかわらず、40GBでとても大きなWebTextデータセット(800万サイト、4,500万リンク)を使って、モデルを学習しました。OpenAIがインターネットから大量なデータを集めていたのはこのモデルの大きな貢献だと思います。また、データが多いと言われても、見たことがないデータもきっとあるし、学習のfine-tuningを少なくするため、zero-shot learningが使われました。学習した完成モデルは6GBで、48層、1,542Mパラメータです。
