

Bidiectional Encoder Representations from Transformers:Google社が開発した事前学習モデル。トランスフォーマーのエンコーダを利用する。Nasked Langage Model(MLM)とNext Sentence Prediction(NSP)という2つのタスクにより事前学習を行う。自然言語処埋におけるモデル。2018年後半発表。 複数の言語処理課題で人問の性能を超えたとして 注目を集めた。
BERTの革新性はTransformerを利用した双方向型の教師なし事前学習を可能にした点にあります。
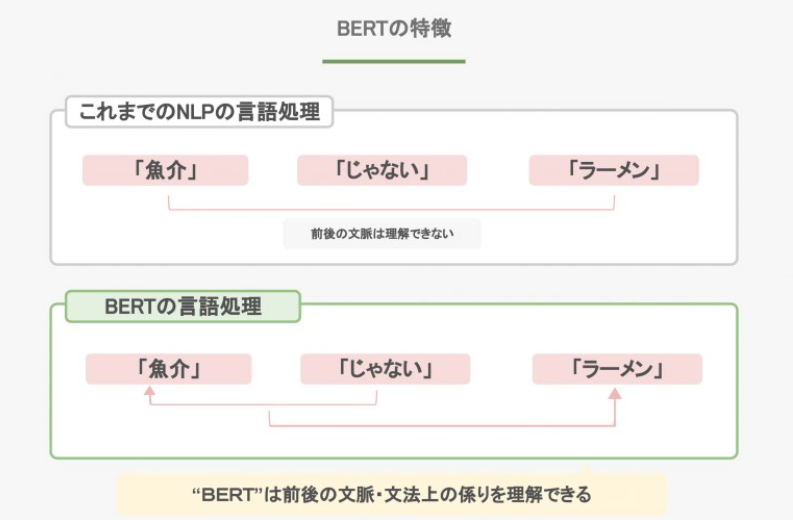
GPT-2もBERTもTransformerの技術を適応していますが、GPT-2はdecoder部分、BERTはencoder部分を重ねた構造です。
BERTはencoder (multi-head attention)を利用するため、空白に単語を埋めるのが得意です。逆に、GPT-2はdecoder(masked multi-head attention)を利用するため、次の単語を予測するのが得意です。かつ、GPT-2が機械が学習したことがないものを予測したいので、zero-shot learningを加えられました。
