不均衡データ(データセットに含まれる各クラスの割合に極端な偏りがあるデータ)を扱う際、少数派のクラスに属するデータをオーバーサンプリングするための手法。
SMOTE(Synthetic Minority Oversampling Technique)は、不均衡データの少数派データを増やす Oversampling の一種です。
少数派のラベルが付いたデータをそのまま複製するのではなく、KNNを用いて増やします。
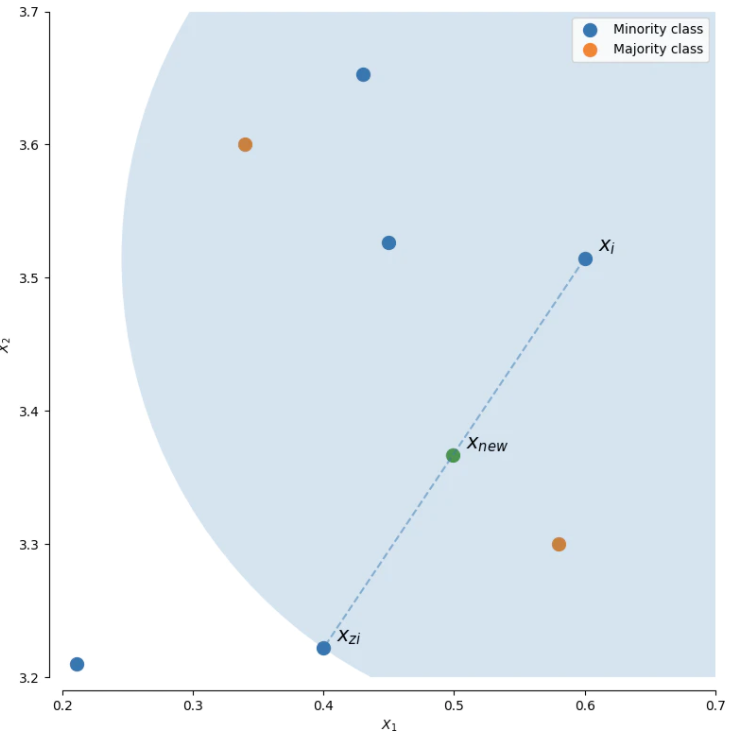
検出した少数派の近接データを線でつなぎ、その線分上の任意の点を人工データとしてランダムに生成します。
まず初期のデータ点 Xi が選ばれます。次に近傍3つからランダムに Xziが選ばれ、2つの線分上の任意の点 Xnewが生成されます。これが基本ロジックです。
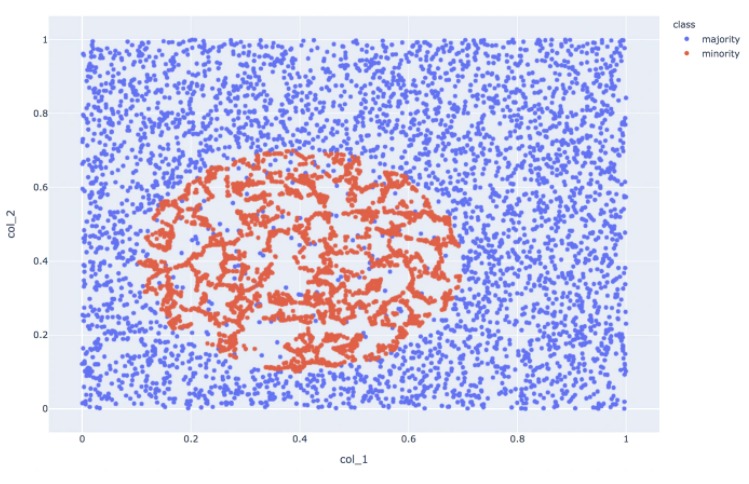
オリジナルデータ
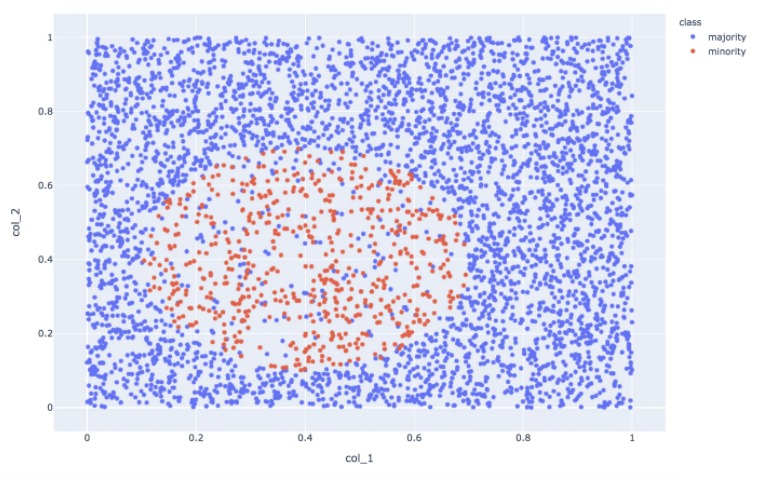
SMOTE適用後