

Q値を最適化する手法。強化学習の代表的なアルゴリズム。
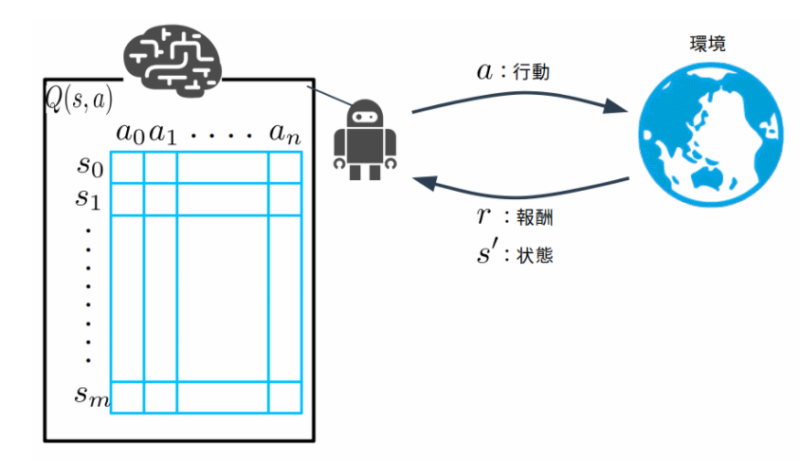
Q学習では、各状態sに対する各行動aのQ値を保存しておくQテーブルQ(s,a)というテーブルを保持しています。(図の左)
Q学習ではこのQテーブルの値を以下の式によって更新します。

この式からわかる通り(赤線部分)、Q学習では遷移先状態s′の最大Q値maxa′Q(s,a′)を使って学習するのが主な特徴となります。
つまり、遷移した先の状態の最も良いところだけを利用します。
そのため楽観的な手法と言われます。ちなみにr+γmaxa′Q(s′,a′)−Q(s,a)をTD誤差といい、 Q学習ではこの誤差を小さくするように学習していきます。
αは学習率といい0〜1の間の値をとるパラメータです。 TD誤差をどれだけ反映させるかを決定します。
γは割引率といい、遷移先の最大Q値をどれだけ利用するかを決めるパラメータです。
