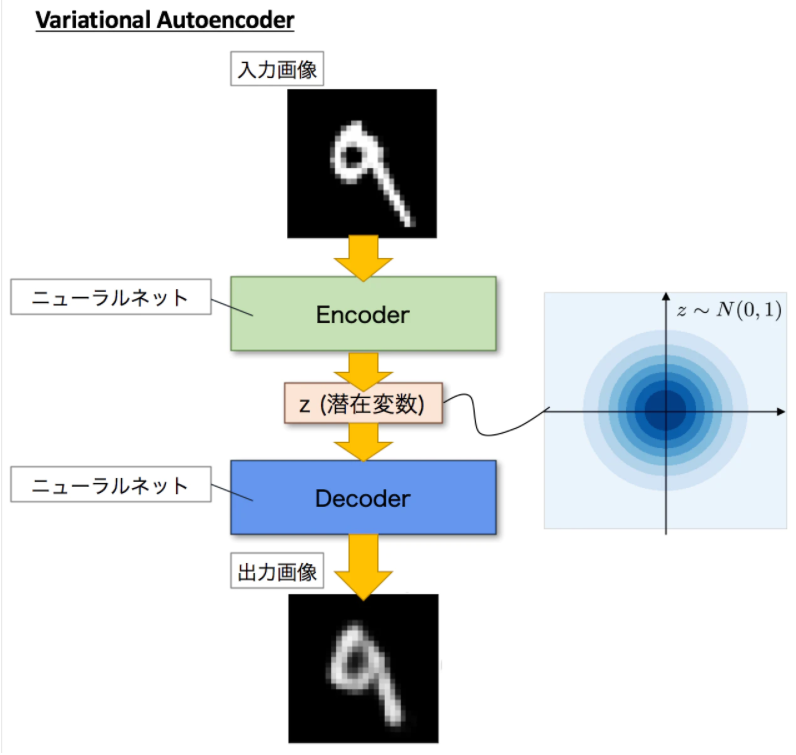
Variational AutoEncoder:入力データを圧縮表現するのではなく、統計分布に変換する。すなわち、平均と分数で表現するように学習する。
VAEはディープラーニングによる生成モデルの1つで、訓練データを元にその特徴を捉えて訓練データセットに似たデータを生成することができます。
オートエンコーダーとは、
- 教師なし学習の一つ。そのため学習時の入力データは訓練データのみで教師データは利用しない。
- データを表現する特徴を獲得するためのニューラルネットワーク。

VAEはこの潜在変数zzに確率分布、通常z∼N(0,1)を仮定したところが大きな違いです。通常のオートエンコーダーだと、何かしら潜在変数zにデータを押し込めているものの、その構造がどうなっているかはよくわかりません。VAEは、潜在変数zzを確率分布という構造に押し込めることを可能にします。
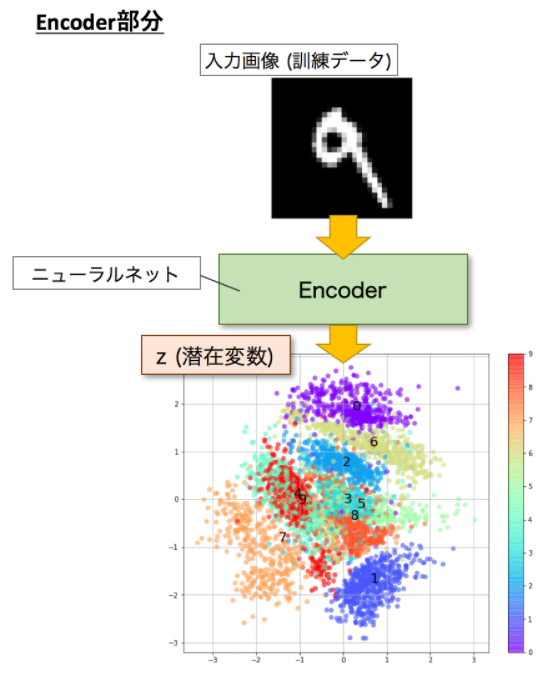
すでに学習済みのEncoderがあったとしてそこに訓練データのデータセットを入れて潜在変数に落としてみます。可視化できるようにzの次元は2次元にします。どうでしょう、訓練データのMNISTデータセットが2次元の正規分布に従う円の上に散らばっている様子が見て取れると思います。また、ここがミソなのですが、教師データのない教師なし学習にもかかわらず同じクラスラベルのデータが近いところに集まっていることも見て取れます。VAEはzが正規分布に従うように設計されており、正規分布に従う乱数を学習時に取り入れているので、この乱数によるブレによって似た形状のものを近くに寄せる効果があるためです。つまり、同じ画像を入力しても毎回ちょっとずれたところにzがプロットされ、そのzからDecoderによって生成する画像を入力画像と同じようにするためです。下記の散布図で数字がテキストでプロットされている位置は、各ラベルの中央です。