

周辺の単語を与えてある単語を予測するモデル。
前後のコンテクストをどの程度利用するかはモデル作成ごとに判断しますが、前後1単語をコンテクストとする場合、例えば下記だと「毎朝」「を」から「?」の単語を推測することになります。

CBOWモデルは出力層において各単語のスコアを出力しますが、そのスコアに対してSoftmax関数を適応することで「確率」を得ることができます。この確率は前後の単語を与えた時にその中央にどの単語が出現するのかを表します。
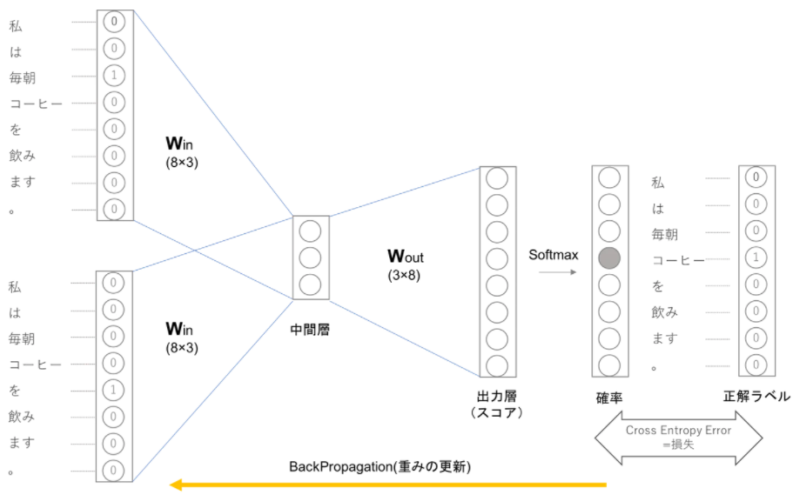
上記の例ではコンテクストは「毎朝」「を」、ニューラルネットワークが予想したい単語が「コーヒー」である例です。この時適切な重みを持ったニューラルネットワークでは「確率」を表すニューロンにおいて正解ニューロンが高くなっていることが期待できます。CBOWの学習では正解ラベルとニューラルネットワークが出力した確率の交差エントロピー誤差を求め、それを損失としてその損失を少なくしていく方向に学習を進めます。
