

k近傍法:k-Nearest Neighbor:主に教師あリ学習の分類に用いられるアルゴリズム。学習データをベクトル空問上にプロットしておき、未知のデータの近くにあるk個の学習デー 夕が属するクラスの多数決結果から未知のデータ のクラスを推定する。
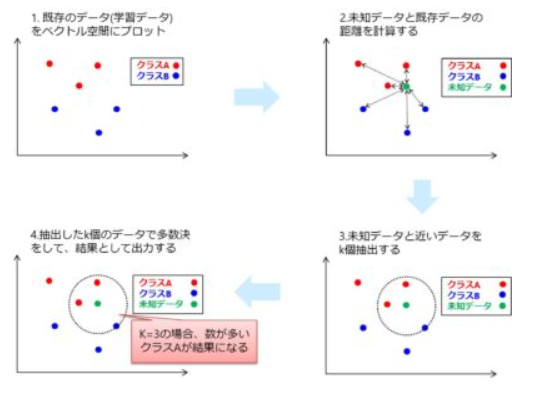
kNNのアルゴリズム
- 既存のデータ(学習データ)をベクトル空間にプロット
- 未知データと既存データの距離を計算する
- 未知データと近いデータをk個抽出する
- 抽出したk個のデータで多数決をして、結果として出力する
【メリット】
- 事前に学習する必要がない
- アルゴリズムがシンプルなのであらゆる問題に適用しやすい
- 予測結果がブラックボックス化されていないので理解しやすい
【デメリット】
- データ量が多い場合、結果の計算に時間がかかってしまう
- 大量のデータをメモリに保持する必要がある
- 次元の高いデータではうまく機能しない
